Also, there's a typo (okay, at least one) in the Iran Agreement (well, in the version posted on medium and as of this writing...).
Ah, this is not part of the order of posting I planned, but...it's not everyday you get to analyze (and find a trivial mistake) in a government document. Since May, I've been writing a really fast, thread safe, fully parallel NLP library because everything else I've tried is either too bloated, too slow to run or train, not thread-safe, too academic, too license encumbered or utilizes too much memory.
More pertinently, I've also been on a life-long quest to figure out some way to effectively summarize documents. Unfortunately, technology is as yet, too far away for my dream intelligent abstract summarizer—every single one of my apparently clever ideas have been unmasked as impostors and pretenders, always self-annihilating in exasperating puffs of failure. Sigh.
However, I have been able to combine ideas that work efficiently on today's machines to arrive at a compromise (plenty more on that in the future). One key idea has been representing text at a layer above just strings, think Google's word2vec but requiring orders of magnitude less computation and data for good results (to be more specific, I use reflective random indexing and directional vectors—which go just a bit beyond bag of words).
Once vectors have been generated (it took my machine 500 ms to do this) and sentences have been tagged with parts of speech, interesting possibilities open up. For example, the magnitude of a vector is an indication of how important a word is, it's similar to word count but orders words in a way that better reflects a word's importance (counts, once you remove common stopwords, are actually infuriatingly good at this already—infuriating because it can be hard to come up with something both better and less dumb). It can also work when few words are repeated, so it's more flexible. Applying this to the Iran document I get as the top 10 most important nouns:
"iran, iaea, fuel, year, centrifuge, reactor, uranium, enrichment, research, joint"
And for verbs:
"include, test, verify, modernise, permit, fabricate, redesign, monitor, intend, store"
This is useful and, being able to select a link, press a hot key and get a small window displaying a similar result for any page will, I think, be a useful capability to have in one's daily information processing toolkit. However, such a summary is limited. One idea is to take the top nouns, find their nearest neighbors but limit them to verbs and adjectives. Here's what I get:
"iran: include/produce/keep is...future, subsequent, consistent
year: keep/conduct/initiate is...more, future, consistent
iaea: monitor/verify/permit is...necessary, regular, daily
fuel: fabricate/intend/meet is...non-destructive, ready, international
uranium: seek/enter/intend is...future, natural, initial
reactor: modernise/redesign/support is...iranian, international, light
centrifuge: occur/remain/continue is...single, small, same
production: include/need/produce is...current, future, consistent
use: include/produce/meeting is...subsequent, initial, destructive
arak: modernise/redesign/support is...light, iranian, international
research: modernise/redesign/support is...international, appropriate, light
jcpoa: declare/implement/verify is...necessary, consistent, continuous
Reading this, I see the results are almost interpretable. There's the IAEA who will monitor Iran and JCPOA too, or something...I'm guessing. There's lots of emphasis on Iran's future and modernization, as well as limitations on uranium production and instruments—centrifuges in particular—in use (at this point, I'd like to point out that I've absolutely not even looked at the original document and don't ever plan to). I don't know if this method will ultimately prove useful; a lot of work involves experimenting with what actually works in day to day use. Some features are simply not worth the cognitive overhead of even just knowing they exist.
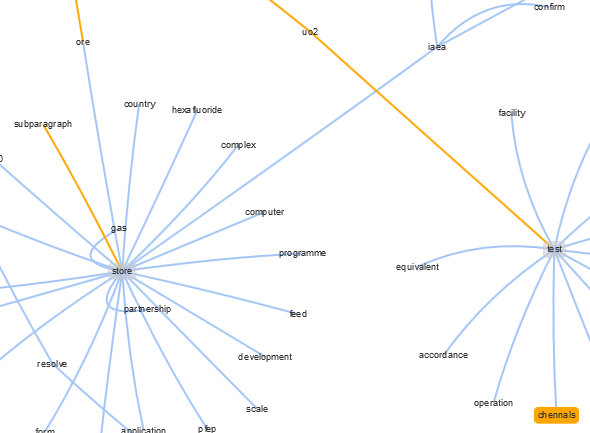
It was at this point I decided to graph the result. The basic idea is: connect all the words with the edge weights computed from pairwise cosine similarities but limit connections to be of the type VERB->NOUN->VERB, then apply a maximum spanning tree to prune the edges and make it actually readable. The idea being, instead of just grouping words by similarity we impose some grammatical structure then hopefully, we get something a bit more structured.
It was while browsing that graph I found the typo:
I'm fairly certain that "Chennals" is not some fancy Nuclear Engineering jargon.

I also built a graph using an algorithm utilizing inputs from a phrase chunker, which then tries to build short understandable phrases (verb dominant phrases can only link to noun phrases), another on sentences and another from paragraphs. The gray shaded and golden edge nodes tend to be most important and are worth zooming into. Around those will be all the most similar phrases/sentences/paragraphs.
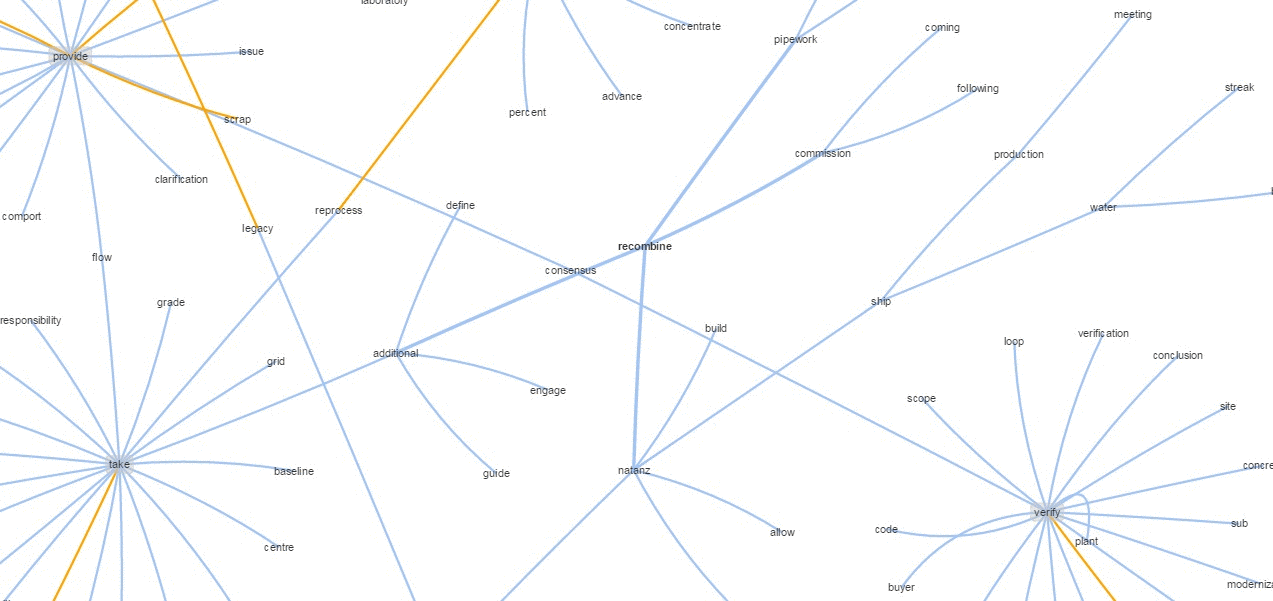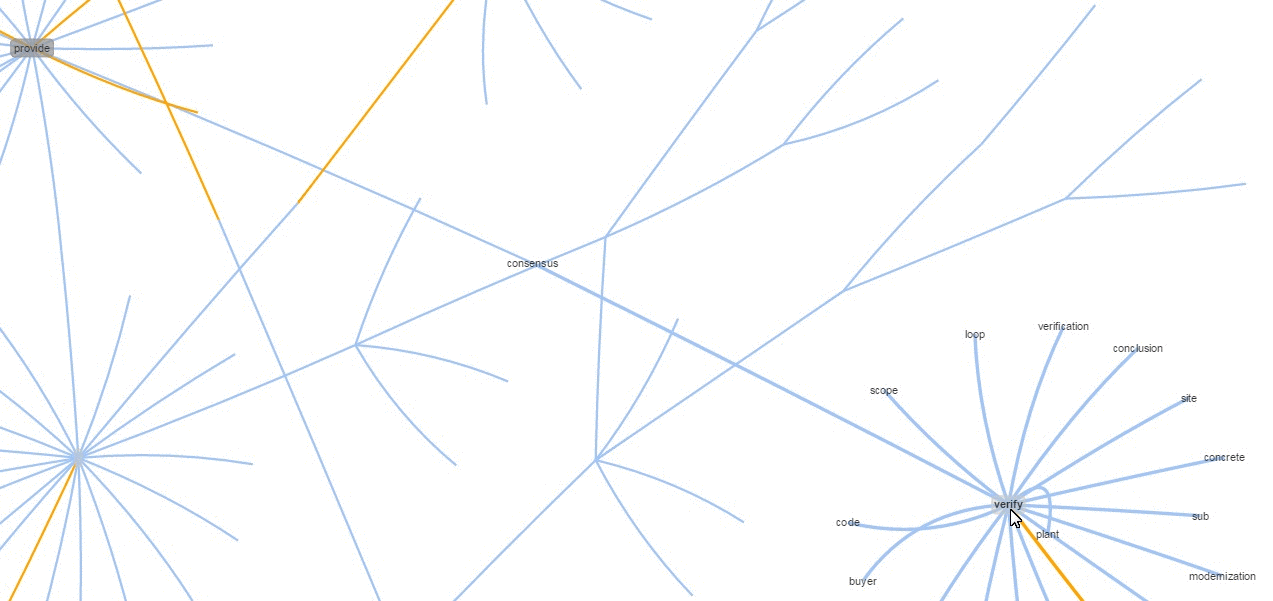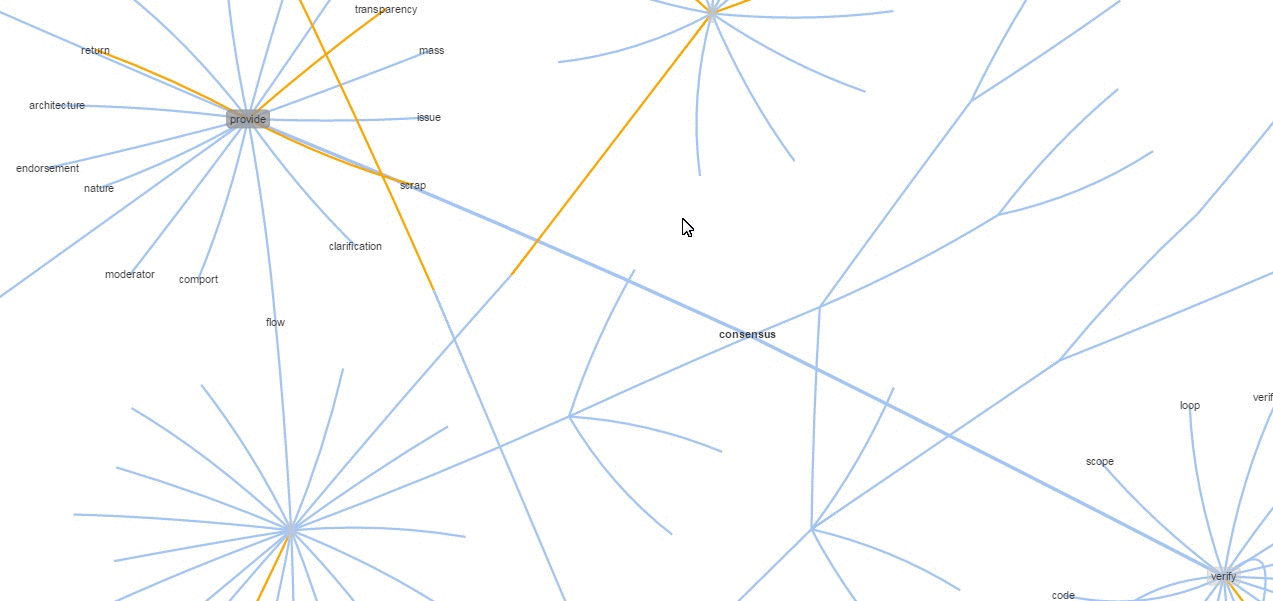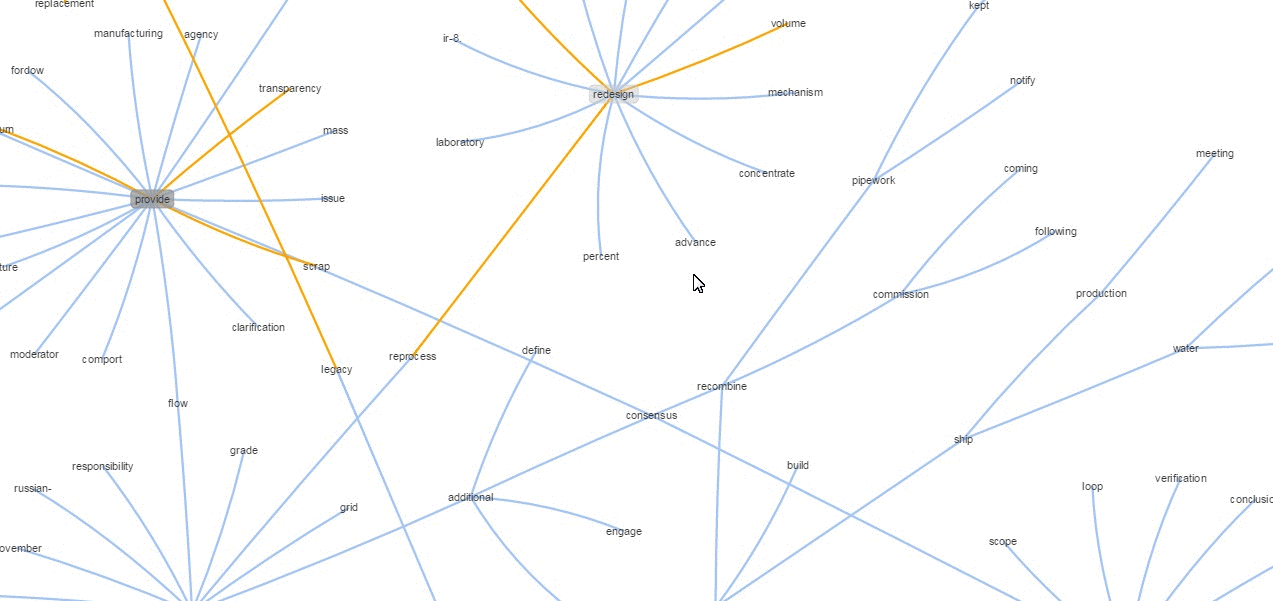
Although this graph visualization was originally meant to compare and contrast (via orthogonal vectors) two or more documents, it works well enough as a summarization tool.
In case you're curious, the graph visualization toolkit I'm using is the excellent vis.js (I welcome any suggestions that'll improve on the sometimes cluttered layout).
The Phrases example is clearly more comprehensible than the single word approach but is not without flaws—there are incomplete thoughts and redundancies. On the other hand, we see that similar phrases are grouped together. It's worth noting that each phrase is represented by a single (200D) vector, hence the groupings are not based on string similarities. And, despite the algorithm not lowcasing all words, the method still groups different cased words together, suggesting that it captures something more than: these words tend to be near each other. It also groups conjugations and phrases in a non-trivial sense, as seen with higher level groupings like:
Those are not just cherry picked samples, as you can see for yourself in the link above. The method holds generally in all documents I've tried. Additionally, it's worth remembering that nodes aren't just grouped by similarity but also must meet the very basic noun phrase-ish ->verb phrase-ish structure I mentioned. The goal is to get something sufficiently comprehensible while being non-linear and more exploratory. By zooming in and out and hiding irrelevant nodes, I can go into more or less depth as I please. This, together with basic question answering on arbitrary text form my very basic approximation of non-linear reading/knowledge acquisition. You can think of skimming as a far distant ancestor of this approach.
Zooming out is, I've found, important when dealing with longer text items (removes clutter). Then, you can click a node, which disapears anything not in its neighborhood, making it easier to read when zoomed in. Other useful features are: the ability to search for a word as well as the ability to hover over nodes to get at their text.
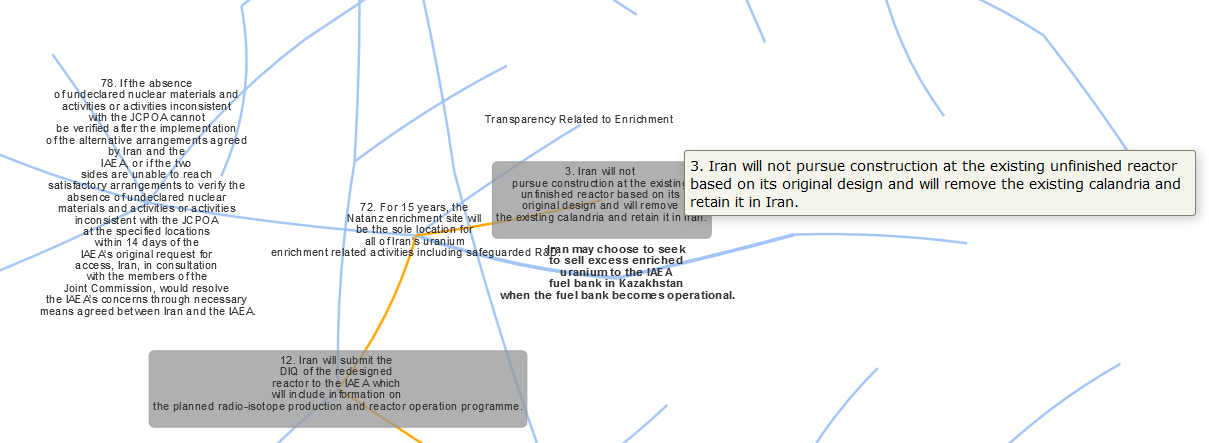
Similar to connecting verbs and nouns, I tried connecting augmented noun phrases (very, very simple rule on how to join phrases to maximize coherence and the same for) verb phrases. With that, for the top 5 phrases, I got:
"2. Iran will modernise the Arak heavy water research reactor to support peaceful nuclear research and radioisotopes production: to be a multi-purpose research reactor comprising radio-isotope production/to support its peaceful nuclear research and production needs and purposes/to monitor Iran ’s production
Iran ’s uranium isotope separation-related research and development or production activities will be exclusively based: to any other future uranium conversion facility which Iran might decide to build/to verify the production/to minimise the production
Iran ’s enrichment and enrichment R&D activities are: to meet the enrichment and enrichment R&D requirements/conducting R&D/to enable future R&D activities
Iran will maintain no more than 1044 IR-1 centrifuge machines: will use no more than 348 IR-1 centrifuges/are only used to replace failed or damaged centrifuges/balancing these IR-1 centrifuges
Iran will permit the IAEA to implement continuous monitoring: will permit the IAEA to implement continuous monitoring/will permit the IAEA to verify the inventory/will allow the IAEA to monitor the quantities
This, I think, is actually a pretty decent summary. It's far from perfect but I've got a much better idea of what's in the document despite it being fairly short. It's also not a verbatim extractive summarizer (since it's constructing and combining phrases which incidentally, also ends up compressing sentences. Although...if a proper generalizing summarizer was a human, this would be like the last common ancestor of humans and mice. Or maybe lice. sigh).
Closer to more typical extractive methods is a very simple method I came up with that generates vectors for sentences using RRI. The method takes the largest magnitude sentence and then finds the nearest sentence that get's within x% of its magnitude (I have x=50%). A sum of all met vectors is kept and a sentence must have > 0.7 similarity with this memory vector. This is repeated for all sentence. I've found that this method tends to create far more fluid summaries than is typical for extractive summarizers while working on almost all document types (even doing a fair job on complex papers and Forum threads). For this Agreement, we get the below at 10% the original document length:
"Destructive and non-destructive testing of this fuel including Post-Irradiation-Examination (PIE) will take place in one of the participating countries outside of Iran and that country will work with Iran to license the subsequent fuel fabricated in Iran for the use in the redesigned reactor under IAEA monitoring.
Iran will not produce or test natural uranium pellets, fuel pins or fuel assemblies, which are specifically designed for the support of the originally designed Arak reactor, designated by the IAEA as IR-40. Iran will store under IAEA continuous monitoring all existing natural uranium pellets and IR-40 fuel assemblies until the modernised Arak reactor becomes operational, at which point these natural uranium pellets and IR-40 fuel assemblies will be converted to UNH, or exchanged with an equivalent quantity of natural uranium.
Iran will continue testing of the IR-6 on single centrifuge machines and its intermediate cascades and will commence testing of up to 30 centrifuge machines from one and a half years before the end of year 10. Iran will proceed from single centrifuge machines and small cascades to intermediate cascades in a logical sequence.
Iran will commence, upon start of implementation of the JCPOA, testing of the IR- 8 on single centrifuge machines and its intermediate cascades and will commence the testing of up to 30 centrifuges machines from one and a half years before the end of year 10. Iran will proceed from single centrifuges to small cascades to intermediate cascades in a logical sequence.
In case of future supply of 19.75% enriched uranium oxide (U3O8) for TRR fuel plates fabrication, all scrap oxide and other forms not in plates that cannot be fabricated into TRR fuel plates, containing uranium enriched to between 5% and 20%, will be transferred, based on a commercial transaction, outside of Iran or diluted to an enrichment level of 3.67% or less within 6 months of its production.
Enriched uranium in fabricated fuel assemblies from other sources outside of Iran for use in Iran’s nuclear research and power reactors, including those which will be fabricated outside of Iran for the initial fuel load of the modernised Arak research reactor, which are certified by the fuel supplier and the appropriate Iranian authority to meet international standards, will not count against the 300 kg UF6 stockpile limit.
This Technical Working Group will also, within one year, work to develop objective technical criteria for assessing whether fabricated fuel and its intermediate products can be readily converted to UF6. Enriched uranium in fabricated fuel assemblies and its intermediate products manufactured in Iran and certified to meet international standards, including those for the modernised Arak research reactor, will not count against the 300 kg UF6 stockpile limit provided the Technical Working Group of the Joint Commission approves that such fuel assemblies and their intermediate products cannot be readily reconverted into UF6. This could for instance be achieved through impurities (e.g. burnable poisons or otherwise) contained in fuels or through the fuel being in a chemical form such that direct conversion back to UF6 would be technically difficult without dissolution and purification.
Iran will permit the IAEA to monitor, through agreed measures that will include containment and surveillance measures, for 25 years, that all uranium ore concentrate produced in Iran or obtained from any other source, is transferred to the uranium conversion facility (UCF) in Esfahan or to any other future uranium conversion facility which Iran might decide to build in Iran within this period.
If the absence of undeclared nuclear materials and activities or activities inconsistent with the JCPOA cannot be verified after the implementation of the alternative arrangements agreed by Iran and the IAEA, or if the two sides are unable to reach satisfactory arrangements to verify the absence of undeclared nuclear materials and activities or activities inconsistent with the JCPOA at the specified locations within 14 days of the IAEA’s original request for access, Iran, in consultation with the members of the Joint Commission, would resolve the IAEA’s concerns through necessary means agreed between Iran and the IAEA. "